环境:Ubuntu 16.04 / python3.5
安装报错Could not import pypandoc - required to package PySpark,进行了如下操作
1 2 3 4 pip install -U pip pip install -U setuptools sudo apt install pandoc #不确定是否起作用 pip install pypandoc
运行时发现未安装 JAVA
1 sudo apt install openjdk-8-jdk
成功运行
Spark 是 UC Berkeley AMP lab (加州大学伯克利分校的 AMP 实验室)所开源的类 Hadoop MapReduce 的通用并行框架,Spark,拥有 Hadoop MapReduce 所具有的优点;但不同于 MapReduce 的是 Job 中间输出结果可以保存在内存中,从而不再需要读写 HDFS,因此 Spark 能更好地适用于数据挖掘与机器学习等需要迭代的 MapReduce 的算法。
spark 支持 Scala,Java,JVM,Python,R。
Spark 的核心是一个对由很多计算任务组成的、运行再多个工作机器或者是一个计算集群上的应用进行调度、分发以及监控的计算引擎。
spark 提供类似 Python 的 pandas 或 R 语言的 data.frame 的操作,但有差异。
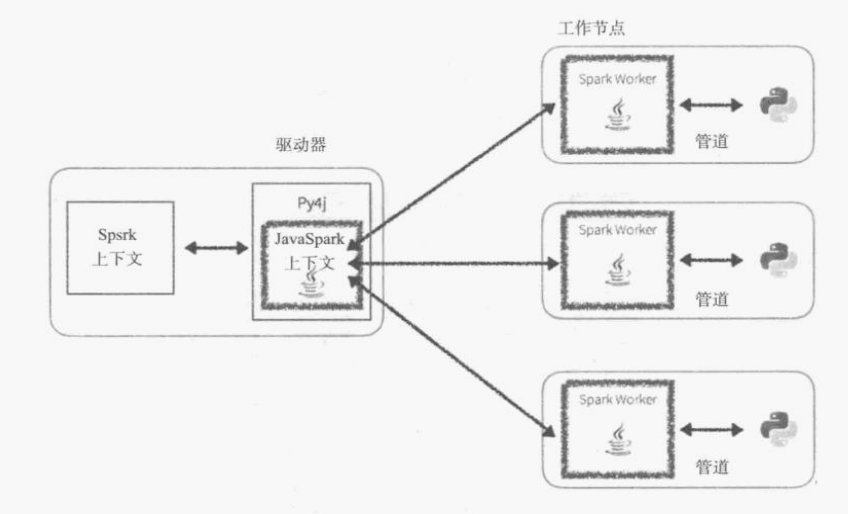
SparkContext 使用 Py4J 启动 JVM 并创建 JavaSparkContext。默认情况下,PySpark 将 SparkContext 作为’sc’提供,因此创建新的 SparkContext 将不起作用。
Spark 应用程序会分离主节点上的单个驱动进程,然后将执行进程分配给多个工作节点。
shuffle 数据非常消耗资源,DAGScheduler 会对此进行优化。
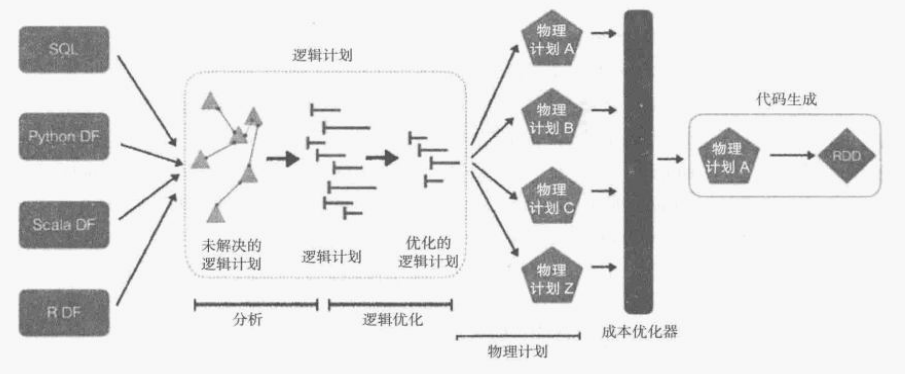
Spark SQL 支持 SQL 查询和 DataFrame API,其核心是 Catalyst 优化器。
saprk 2.0 中 Sparksession 是读取数据,处理元数据,配置绘画和管理集群资源的入口。
创建 SparkContext
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class pyspark .SparkContext ( master = None, appName = None, sparkHome = None, pyFiles = None, environment = None, batchSize = 0 , serializer = PickleSerializer() , conf = None, gateway = None, jsc = None, profiler_cls = <class 'pyspark.profiler.BasicProfiler' > ) from pyspark import SparkContext sc = SparkContext("local", "First App")
以下是 SparkContext 的参数具体含义:
Master- 连接到的集群的 URL。appName- 工作名称。sparkHome - Spark 安装目录。pyFiles - 要发送到集群并添加到 PYTHONPATH 的。zip 或。py 文件。environment - 工作节点环境变量。batchSize - 表示为单个 Java 对象的 Python 对象的数量。设置 1 以禁用批处理,设置 0 以根据对象大小自动选择批处理大小,或设置为-1 以使用无限批处理大小。serializer- RDD 序列化器。Conf - SparkConf的一个对象,用于设置所有 Spark 属性。gateway - 使用现有网关和 JVM,否则初始化新 JVM。JSC - JavaSparkContext 实例。profiler_cls - 用于进行性能分析的一类自定义 Profiler(默认为pyspark.profiler.BasicProfiler)。
RDD(弹性分布式数据集,Resilient Distributed Dataset),是 JVM 对象的分布式集合。
RDD 支持多种数据格式读取:文本,parquest,JSON,Hive tables 以及使用 JDBC 驱动可以读取的数据库。Spark 可以自动处理压缩包。
从文件中读取的数据为 MapPartitionRDD,使用。parallelize() 方式获得的是 ParallelCollectionRDD。
RDD 无 schema,可以混用任何数据类型。
定义纯 Python 方法会降低程序的速度,Spark 需要在 Python 解释器和 JVM 之间切换,因此尽可能使用 Spark 内置的功能。
作用域:每个执行器从驱动程序中获得一份变量和方法的副本,执行器对这些变量或方法的修改其他执行者是不可见的。
转换包括映射、筛选、连接、转换数据集中的值。
.map()
对 RDD 的每个元素进行转换,通常搭配lambda,输出为多列时需要打包成一个 tuple
.map(lambda row: (row[16], int(row[16])))
.filter()
从数据集中选择元素:.filter(lambda row: row[16] == '2014' and row[21] == '0')
flatMap()
把所有结果扁平化简单拼接
.distinct()
返回 distinct 值,开销大,慎用
.sample()
sample(isReplace, fraction, seed)
.leftOuterJoin()
和 SQL 中一样,a.leftOuterJoin(b),高开销,慎用。.join()为内连接,.intersection()返回相同的记录
.repartition()
重新对数据集进行分区,改变分区数量,会重组数据,开销大,慎用。
take()
返回单个数据分区的前 n 行。可以使用 takeSample()取随机样本。
collect()
reduce()
reduce() 传递的函数需要不受元素顺序和操作符顺序的影响,如x+y没问题,x/y不行
count()
统计数量,只返回统计值,不会将数据集返回到驱动程序。如果数据集是 key-value 形式,可以使用 countBykey()方式获取不同键的计数。
saveAsTextFile()
把 RDD 保存为文本文件,但不可使用open()读取,要使用textFile()读取。所有数据以字符串形式读取,想要转换为数字要自己进行解析。
foreach()
类似map(),对每个元素进行操作,但不要求返回值为 RDD 支持的类型,可以保存到 pyspark 本身不支持的数据库。
Spark 对 RDD 的计算是惰性的。
1 2 3 lines = sc.textFile("README.md" ) pythonLines = lines.filter(lambda line: "Python" in line) pythonLines.first()
上例中,第 1,2 行的语句(转换操作)都不会真正计算 RDD,只有再第三行使用到 RDD(行动操作)的时候,才去按照既定的规则扫描文本。若是在第 1 句就讲文本读进内存,而第 2 句又过滤了大量文本,浪费资源。
默认情况下,每次行动操作时会重新计算 RDD,除非使用RDD.persist()将其缓存。
转换操作:输入 RDD(可能有多个),返回 RDD
行动操作:输出结果,会触发实际的计算
Spark 会维护一个lineage graph/谱系图来记录不同的 RDD 之间的关系,需要这些信息来按需计算 RDD。
传递函数时需要注意,当传递的是某个对象的成员或者包含某个对象中字段的引用,Spark 会把整个对象都发送到工作节点上 ,替代方案是将所需字段保存为局部变量再传递。
Spark 2.0SparkSession来替代SQLContext。各种 Spark 的上下文语境HiveContext、SQLContext、StreamingContext和SparkContext都被整合到了SparkSession,这样一来,只需要将此会话作为读取数据的入口点,和元数据、配置以及群集资源管理一起来使用。
Spark SQL 引擎既有基于规则的优化,也有基于成本的优化,包括但不限于谓词下推和列精简。
在 spark 1.x 中使用 sqlContext
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from pyspark.sql import SparkSessionspark = SparkSession \ .builder \ .appName("Python Spark SQL basic example" ) \ .config("spark.some.config.option" , "some-value" ) \ .getOrCreate() stringJSONRDD = sc.parallelize((""" { "id": "123", "name": "Katie", "age": 19, "eyeColor": "brown" }""" , """{ "id": "234", "name": "Michael", "age": 22, "eyeColor": "green" }""" , """{ "id": "345", "name": "Simone", "age": 23, "eyeColor": "blue" }""" )) swimmersJSON = spark.read.json(stringJSONRDD) swimmersJSON.createOrReplaceTempView("swimmersJSON" ) swimmersJSON.show() spark.sql("select * from swimmersJSON" ).collect()
Spark 使用反射自动推断数据类型
1 2 swimmersJSON.printSchema()
指定类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from pyspark.sql.types import *stringCSVRDD = sc.parallelize([(123 , 'Katie' , 19 , 'brown' ), (234 , 'Michael' , 22 , 'green' ), (345 , 'Simone' , 23 , 'blue' )]) schema = StructType([ StructField("id" , LongType(), True ), StructField("name" , StringType(), True ), StructField("age" , LongType(), True ), StructField("eyeColor" , StringType(), True ) ]) swimmers = spark.createDataFrame(stringCSVRDD, schema) swimmers.createOrReplaceTempView("swimmers" ) swimmers.printSchema()
1 2 3 4 5 6 7 8 swimmers.count() spark.sql("select count(1) from swimmers" ).show() swimmers.select(swimmers.id, swimmers.age).filter(swimmers.age == 22 ).show() swimmers.select("id" , "age" ).filter("age = 22" ).show() spark.sql("select id, age from swimmers where age = 22" ).show() spark.sql("select id, age from swimmers where age = 22" ).show()
机场数据
航班数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 flightPerfFilePath = "spark/flights/departuredelays.csv" airportsFilePath = "spark/flights/airport-codes-na.txt" airports = spark.read.csv(airportsFilePath, header='true' , inferSchema='true' , sep='\t' ) airports.createOrReplaceTempView("airports" ) flightPerf = spark.read.csv(flightPerfFilePath, header='true' ) flightPerf.createOrReplaceTempView("FlightPerformance" ) flightPerf.cache()
1 2 3 4 5 6 7 8 9 10 spark.sql(""" select a.City, f.origin, sum(f.delay) as Delays from FlightPerformance f join airports a on a.IATA = f.origin where a.State = 'WA' group by a.City, f.origin order by sum(f.delay) desc """ ).show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 df = spark.createDataFrame([ (1 , 144.5 , 5.9 , 33 , 'M' ), (2 , 167.2 , 5.4 , 45 , 'M' ), (3 , 124.1 , 5.2 , 23 , 'F' ), (4 , 144.5 , 5.9 , 33 , 'M' ), (5 , 133.2 , 5.7 , 54 , 'F' ), (3 , 124.1 , 5.2 , 23 , 'F' ), (5 , 129.2 , 5.3 , 42 , 'M' ), ], ['id' , 'weight' , 'height' , 'age' , 'gender' ]) print('Count of rows: {0}' .format(df.count())) print('Count of distinct rows: {0}' .format(df.distinct().count())) df = df.dropDuplicates() df.show() print('Count of ids: {0}' .format(df.count())) print('Count of distinct ids: {0}' .format( df.select([c for c in df.columns if c != 'id' ]).distinct().count())) df = df.dropDuplicates(subset=[c for c in df.columns if c != 'id' ]) df.show() import pyspark.sql.functions as fndf.agg( fn.count('id' ).alias('count' ), fn.countDistinct('id' ).alias('distinct' ) ).show() df.withColumn('new_id' , fn.monotonically_increasing_id()).show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 df_miss = spark.createDataFrame([ (1 , 143.5 , 5.6 , 28 , 'M' , 100000 ), (2 , 167.2 , 5.4 , 45 , 'M' , None ), (3 , None , 5.2 , None , None , None ), (4 , 144.5 , 5.9 , 33 , 'M' , None ), (5 , 133.2 , 5.7 , 54 , 'F' , None ), (6 , 124.1 , 5.2 , None , 'F' , None ), (7 , 129.2 , 5.3 , 42 , 'M' , 76000 ), ], ['id' , 'weight' , 'height' , 'age' , 'gender' , 'income' ]) df_miss.rdd.map( lambda row: (row['id' ], sum([c == None for c in row])) ).collect() df_miss.where('id == 3' ).show() df_miss.agg(*[ (1 - (fn.count(c) / fn.count('*' ))).alias(c + '_missing' ) for c in df_miss.columns ]).show() df_miss_no_income = df_miss.select([c for c in df_miss.columns if c != 'income' ]) df_miss_no_income.show() df_miss_no_income.dropna(thresh=3 ).show() means = df_miss_no_income.agg( *[fn.mean(c).alias(c) for c in df_miss_no_income.columns if c != 'gender' ] ).toPandas().to_dict('records' )[0 ] means['gender' ] = 'missing' df_miss_no_income.fillna(means).show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 df_outliers = spark.createDataFrame([ (1 , 143.5 , 5.3 , 28 ), (2 , 154.2 , 5.5 , 45 ), (3 , 342.3 , 5.1 , 99 ), (4 , 144.5 , 5.5 , 33 ), (5 , 133.2 , 5.4 , 54 ), (6 , 124.1 , 5.1 , 21 ), (7 , 129.2 , 5.3 , 42 ), ], ['id' , 'weight' , 'height' , 'age' ]) cols = ['weight' , 'height' , 'age' ] bounds = {} for col in cols: quantiles = df_outliers.approxQuantile(col, [0.25 , 0.75 ], 0.05 ) IQR = quantiles[1 ] - quantiles[0 ] bounds[col] = [quantiles[0 ] - 1.5 * IQR, quantiles[1 ] + 1.5 * IQR] outliers = df_outliers.select(*['id' ] + [ ( (df_outliers[c] < bounds[c][0 ]) | (df_outliers[c] > bounds[c][1 ]) ).alias(c + '_o' ) for c in cols ]) outliers.show() df_outliers = df_outliers.join(outliers, on='id' ) df_outliers.filter('weight_o' ).select('id' , 'weight' ).show() df_outliers.filter('age_o' ).select('id' , 'age' ).show()
1 2 3 4 5 6 fraud_df.groupby('gender' ).count().show() numerical = ['balance' , 'numTrans' , 'numIntlTrans' ] desc = fraud_df.describe(numerical) desc.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 numerical = ['balance' , 'numTrans' , 'numIntlTrans' ] n_numerical = len(numerical) corr = [] for i in range(0 , n_numerical): temp = [None ] * i for j in range(i, n_numerical): temp.append(fraud_df.corr(numerical[i], numerical[j])) corr.append(temp) print(corr)
可使用 matplotlib 不详细展开
ML 和 MLlib 都是 Spark 中的机器学习库,目前常用的机器学习功能 2 个库都能满足需求。
ML 从 Spark 2.0 开始作为主要的机器学习库, 因为 ML 功能更全面更灵活,未来会主要支持 ML,MLlib 很有可能会被废弃(据说可能是在 spark3.0 中 deprecated)。
ML 主要操作的是 DataFrame, 而 MLlib 操作的是 RDD,也就是说二者面向的数据集不一样。相比于 MLlib 在 RDD 提供的基础操作,ML 在 DataFrame 上的抽象级别更高,数据和操作耦合度更低。
DataFrame 和 RDD 什么关系?DataFrame 是 Dataset 的子集,也就是 Dataset[Row], 而 DataSet 是对 RDD 的封装,对 SQL 之类的操作做了很多优化。
相比于 MLlib 在 RDD 提供的基础操作,ML 在 DataFrame 上的抽象级别更高,数据和操作耦合度更低。
ML 中的操作可以使用 pipeline, 跟 sklearn 一样,可以把很多操作(算法/特征提取/特征转换)以管道的形式串起来,然后让数据在这个管道中流动。
ML 中无论是什么模型,都提供了统一的算法操作接口,比如模型训练都是fit;不像 MLlib 中不同模型会有各种各样的trainXXX。
MLlib 在 spark2.0 之后进入维护状态, 这个状态通常只修复 BUG 不增加新功能。
MLlib 包括了三个核心机器学习功能:
数据准备:特征提取、变换、选择、分类特征的散列和一些自然语言处理方法。
机器学习算法:实现了一些流行和高级的回归,分类和聚类算法。
实用程序:统计方法,如描述性统计、卡方检验、线性代数(稀疏稠密矩阵和向量)
MLlib 过去使用 SGD 算法求解,在 Spark 2.0 后被废除,使用 LogisticRegressionWithBFGS 模型,该模型用的是 L-BGFS 优化方法。
评价指标
1 2 3 4 5 6 7 8 import pyspark.mllib.evaluation as evLR_evaluation = ev.BinaryClassificationMetrics(LR_results) print('Area under PR: {0:.2f}' \ .format(LR_evaluation.areaUnderPR)) print('Area under ROC: {0:.2f}' \ .format(LR_evaluation.areaUnderROC)) LR_evaluation.unpersist()
在顶层,该软件包公开了三个主要的抽象类:转换器(Transformer)、评估器(Estimator)和管道(Pipeline)。
spark.ml.feature 中提供了许多转换器
Binarizer:根据指定的阈值将连续变量转换为对应的二进制值
Bucketizer:根据阈值列表,将连续变量转换为多项值
QuantileDiscretizer:类似 Bucketizer,传递一个 numBuckets 参数,计算分位数进行数据划分
ChiSqSelector:根据卡方检验选择预定义数量的特征
CountVectorizer
DCT:离散余弦变换取实数值向量,并返回相同长度的向量
ElementwiseProduct:逐元素乘积
HashingTF:输入为标记文本的列表,返回一个带有计数的有预订长度的向量
MaxAbsScaler:将数据调整到 [-1, 1]
MinMaxScaler:将数据缩放到 [0, 1]
Normalizer
NGram:输入为标记文本的列表(一个词为一个元素),返回结果包含 n-gram 列表
OneHotEncoder
PCA
PolynominalExpansion:执行向量的多项式扩展,可以创建特征关联项
RFormula:可以传递一个公式,如 vec ~ x*3 + y,将产生 vec 列
StandardScaler:标准化,均值为 0,标准差为 1
VectorAssembler:将多个数字列合并为一列向量
1 2 3 4 5 6 7 8 df = spark.createDataFrame( [(12 ,10 ,3 ), (1 ,4 ,2 )], ['a' ,'b' ,'c' ]) ft.VectorAssembler(inputCols=['a' ,'b' ,'c' ], outputCol='features' )\ .transform(df)\ .select('features' )\ .collect()
输出为
1 2 [Row(features=DenseVector([12.0, 10.0, 3.0])), Row(features=DenseVector([1.0, 4.0, 2.0]))]
ML 包提供了 7 种分类模型
LogisticRegression:目前仅支持二分类
DecisionTreeClassifier
RandomForestClassifier:支持多分类
GBTClassifier:用于分类的梯度提升决策树模型,支持二进制标签,连续特征和分类特征
NaiveBayes:支持多分类
MultilayerPerceptionClassifier
OneVsRest:使用 one vs rest 策略将多分类问题转换为二分类
ML 包提供 7 种回归模型
LinearRegression
AFTSurvivalRegression:加速失效时间生存回归模型。它是一个参数化模型,假设其中一个特征的边际效应加速或减缓了预期寿命,适合具有明确阶段的过程。
DecisionTreeRegression
RandomForestRegression
GBTRegression
GeneralizedLinearRegression:支持 gaussian、binomial、gamma 和 poisson 分布
IsotonicRegression:保序回归,拟合一个非递减的函数,适用于有序和递增的数据集
ML 包提供 4 种聚类模型
KMeans:将样本分为 K 个簇,迭代地划分,使得簇内样本和所属簇的质点之间的距离平方和最小
BisectingKMeans:二分 K 均值算法,结合了 K 均值聚类和层级聚类算法。最初将所有样本作为一个簇,逐步迭代分解为 K 个簇
GaussianMixture:高斯混合模型,使用具有未知参数的 k 个高斯分布刻画数据集,使用期望最大算法寻找参数。对于特征数多的问题,可能表现不佳
LDA
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 import pyspark.sql.types as typlabels = [ ('INFANT_ALIVE_AT_REPORT' , typ.IntegerType()), ('BIRTH_PLACE' , typ.StringType()), ('MOTHER_AGE_YEARS' , typ.IntegerType()), ('FATHER_COMBINED_AGE' , typ.IntegerType()), ('CIG_BEFORE' , typ.IntegerType()), ('CIG_1_TRI' , typ.IntegerType()), ('CIG_2_TRI' , typ.IntegerType()), ('CIG_3_TRI' , typ.IntegerType()), ('MOTHER_HEIGHT_IN' , typ.IntegerType()), ('MOTHER_PRE_WEIGHT' , typ.IntegerType()), ('MOTHER_DELIVERY_WEIGHT' , typ.IntegerType()), ('MOTHER_WEIGHT_GAIN' , typ.IntegerType()), ('DIABETES_PRE' , typ.IntegerType()), ('DIABETES_GEST' , typ.IntegerType()), ('HYP_TENS_PRE' , typ.IntegerType()), ('HYP_TENS_GEST' , typ.IntegerType()), ('PREV_BIRTH_PRETERM' , typ.IntegerType()) ] schema = typ.StructType([ typ.StructField(e[0 ], e[1 ], False ) for e in labels ]) births = spark.read.csv('births_transformed.csv.gz' , header=True , schema=schema) import pyspark.ml.feature as ftbirths = births.withColumn('BIRTH_PLACE_INT' , births['BIRTH_PLACE' ].cast(typ.IntegerType())) encoder = ft.OneHotEncoder( inputCol='BIRTH_PLACE_INT' , outputCol='BIRTH_PLACE_VEC' ) featuresCreator = ft.VectorAssembler( inputCols=[ col[0 ] for col in labels[2 :]] + \ [encoder.getOutputCol()], outputCol='features' ) import pyspark.ml.classification as cllogistic = cl.LogisticRegression( maxIter=10 , regParam=0.01 , labelCol='INFANT_ALIVE_AT_REPORT' ) from pyspark.ml import Pipelinepipeline = Pipeline(stages=[ encoder, featuresCreator, logistic ]) births_train, births_test = births \ .randomSplit([0.7 , 0.3 ], seed=666 ) model = pipeline.fit(births_train) test_model = model.transform(births_test) test_model.take(1 )
评估模型性能
1 2 3 4 5 6 7 8 9 import pyspark.ml.evaluation as evevaluator = ev.BinaryClassificationEvaluator( rawPredictionCol='probability' , labelCol='INFANT_ALIVE_AT_REPORT' ) print(evaluator.evaluate(test_model, {evaluator.metricName: 'areaUnderROC' })) print(evaluator.evaluate(test_model, {evaluator.metricName: 'areaUnderPR' }))
保存/加载模型
1 2 3 4 5 6 7 8 9 10 pipelinePath = './infant_oneHotEncoder_Logistic_Pipeline' pipeline.write().overwrite().save(pipelinePath) from pyspark.ml import PipelineModelmodelPath = './infant_oneHotEncoder_Logistic_PipelineModel' model.write().overwrite().save(modelPath) loadedPipelineModel = PipelineModel.load(modelPath) test_loadedModel = loadedPipelineModel.transform(births_test)
调(lian)参(dan)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import pyspark.ml.tuning as tunelogistic = cl.LogisticRegression( labelCol='INFANT_ALIVE_AT_REPORT' ) grid = tune.ParamGridBuilder() \ .addGrid(logistic.maxIter, [2 , 10 , 50 ]) \ .addGrid(logistic.regParam, [0.01 , 0.05 , 0.3 ]) \ .build() evaluator = ev.BinaryClassificationEvaluator( rawPredictionCol='probability' , labelCol='INFANT_ALIVE_AT_REPORT' ) cv = tune.CrossValidator( estimator=logistic, estimatorParamMaps=grid, evaluator=evaluator ) pipeline = Pipeline(stages=[encoder,featuresCreator]) data_transformer = pipeline.fit(births_train) cvModel = cv.fit(data_transformer.transform(births_train)) data_train = data_transformer \ .transform(births_test) results = cvModel.transform(data_train) print(evaluator.evaluate(results, {evaluator.metricName: 'areaUnderROC' })) print(evaluator.evaluate(results, {evaluator.metricName: 'areaUnderPR' }))
获取最佳模型的参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 results = [ ( [ {key.name: paramValue} for key, paramValue in zip( params.keys(), params.values()) ], metric ) for params, metric in zip( cvModel.getEstimatorParamMaps(), cvModel.avgMetrics ) ] sorted(results, key=lambda el: el[1 ], reverse=True )[0 ]
// TODO