defcookies_convert(raw_cookies): cookies = {} for line in raw_cookies.split(';'): key, value = line.split('=', 1) # 1代表只分一次,得到两个数据 cookies[key] = value return cookies
defarea_query(area_code, retry=0): if retry == 5: print('Retry too many times! Area code: ', area_code) returnNone area_resp = requests.post(area_url, {'code': area_code}, cookies=cookies) try: data = json.loads(area_resp.text)['result'] except json.decoder.JSONDecodeError: data = area_query(area_code, retry+1) return data
defget_area_map(): area_map = {} with open(area_map_file, 'w') as f: area_code = '000000' prov_data = area_query(area_code) for povince in prov_data: prov_name = povince['region_name'] prov_code = povince['region_code'] city_data = area_query(prov_code) for city in city_data: city_name = city['region_name'] city_code = city['region_code'] # 加一个延时,避免查询频率过高被封 time.sleep(random.random()) country_data = area_query(city_code) for country in country_data: country_name = country['region_name'] country_code = country['region_code'] # 代码或名称为空时跳过 ifnot (country_name and country_code): continue area_map[country_code] = prov_name + \ '/'+city_name+'/'+country_name print(country_code, area_map[country_code]) f.write(country_code+'\t'+area_map[country_code]+'\n') return area_map
# 查询行政区划代码和并称并保存 ifnot os.path.exists(area_map_file): print('Area code file does not exist, uncomment the line below to get it.') # area_map = get_area_map()
# 读取行政区划代码用于查询风险等级 with open(area_map_file, 'r') as f: areas = f.readlines()
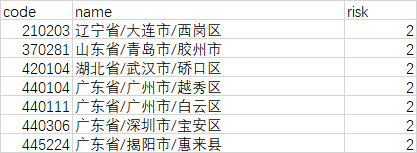
# 读取已经查询过的数据,避免重复查询 with open('risk.csv', 'r+', encoding='utf-8') as csvfile: reader = csv.DictReader(csvfile) try: exist_code = set([row['code'] for row in reader]) except: # 第一次要写入表头 writer = csv.writer(csvfile) writer.writerow(["code","name","risk"]) exist_code = set()
with open('risk.csv', 'a+', newline='', encoding='utf-8') as csvfile: writer = csv.writer(csvfile) for i, line in enumerate(areas): code, name = line.split() # 跳过查询过的地区 if code in exist_code: continue risk = query_risk(code, name) # 使用 -1 表示未知 if risk == 'null': risk = -1 print(str(i)+'/'+str(len(areas)),code,name,risk) writer.writerow([code,name,risk])