在 MySQL 的规模越来越大时,如何保证快速、高效且经济。
什么是可扩展性
容易混淆的用词:可扩展性,高可用性,性能。
可扩展性就是能过够通过增加资源提升容量(工作效率)的能力。表明了当需要增加资源以执行更过工作时系统能够划算地提供等同提升(equal bang for the buck)的能力。另一种说法是,可扩展性是当增加资源以处理负载和增加容量时系统能够获得的投入产出比。
大部分系统都没办法做到线性扩展,越高的扩展系数导致越大的线性偏差,最终达到临界点。—— 详见通用可扩展定律(Universal Scalability Law,USL)
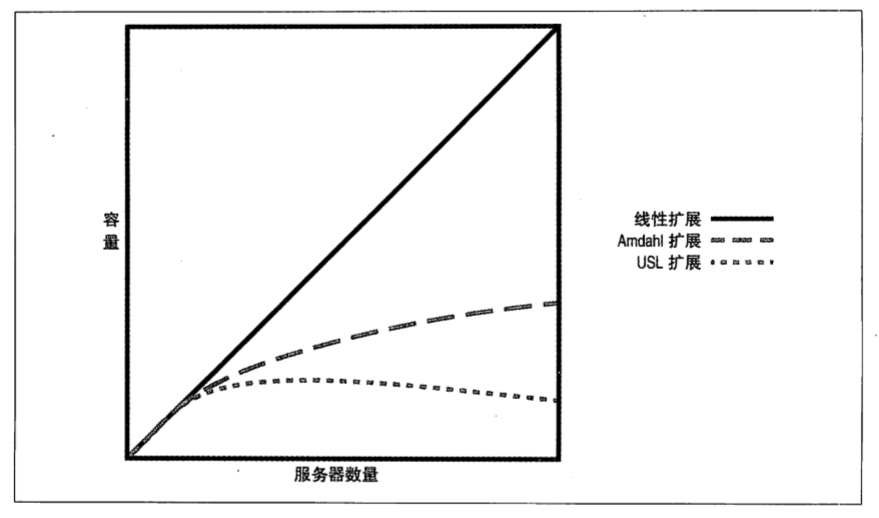
USL 也可能失效,如 USL 不允许比线性更好的可扩展性,但现实中可能通过增加资源使一部分 IO 密集型工作变成纯内存工作,获得超越线性的性能扩展。还有一些情况,当系统或数据集大小改变时算法的复杂度可能改变。
扩展 MySQL
- 垂直扩展/向上扩展:买更强悍的机器
- 水平扩展/向外扩展:将任务分配到更多的机器
- 向内扩展:清理或归档很少或不需要的数据
帮助规划可扩展性的问题:
- 应用的功能完成了多少? 许多可扩展性解决方案可能会导致实现某些功能更加困难。如果应用的某些核心功能还没开始实现很难确定扩展方案。喵,设计和实现相互依赖,只能滚动前进了。
- 预期的最大负载是多少? 应用应当在最大负载下也能正常工作。、
- 如果依赖系统的每个部分来分担负载,在某个部分失效时会发生什么呢? 如果依赖备库来分担读负载,当其中一个失效时,是否还能正常处理请求?是否需要禁用某些功能?
向上扩展
理想情况下是计划先行、拥有足够的开发者和预算,但实际情况并非如此。在深入 MySQL 扩展之前可以做一些准备工作:
- 性能优化
- 购买更强的硬件:这在软件生命周期的早期有效。当前合理的“收益递减点”的机器配置大约是 256GB RAM,32 核以及一个 PCIe flash(存储)驱动。如果继续提升,性价比降低。(注意书的时代背景,数据可能过时)
向外扩展
向外扩展策略划分为三个部分:复制、拆分以及数据分片。
最常见的做法是通过复制吧数据分发到多个备库,备库用于读扩展。
另一种比较常见的向外扩展方法是将工作负载分布到多个“节点”,一个节点就是一个功能部件,可能是一台服务器,也可以是多台机器构成,多数情况下,一个节点内的所有服务器应该拥有相同的数据。书中推荐把“主-主复制”架构作为一个节点。
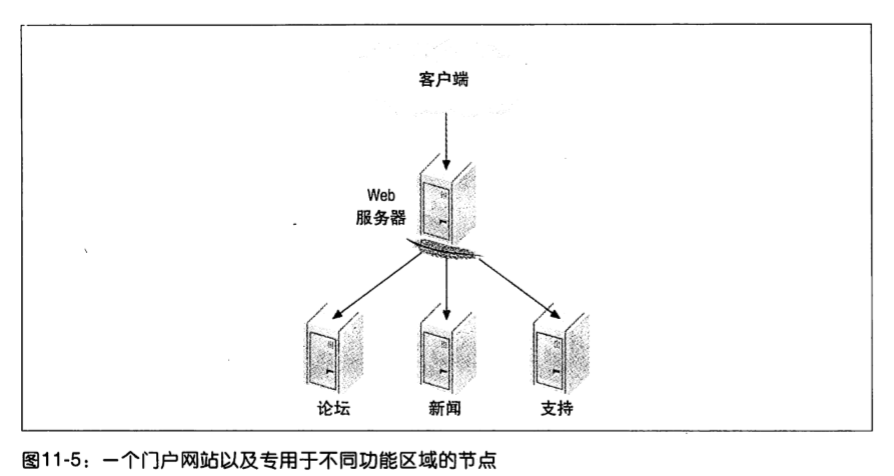
按功能拆分
按功能拆分意味着不同的节点执行不同的任务。但不能通过功能划分无限地扩展,如果一个功能区域被绑定到单个 MySQL 节点,就只能进行垂直扩展。
数据分片
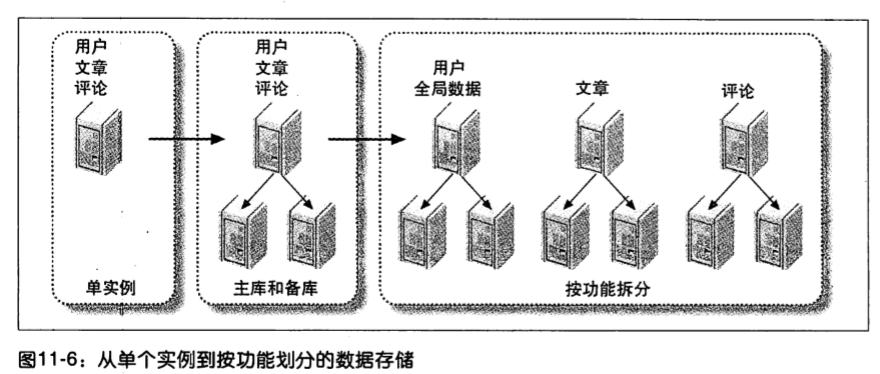
数据分片是最通用最成功的方法,它将数据分割成小块存储到不同的节点中。
数据分片通常和功能划分结合使用, 部分全局数据(城市列表或登录数据)不会被分片。
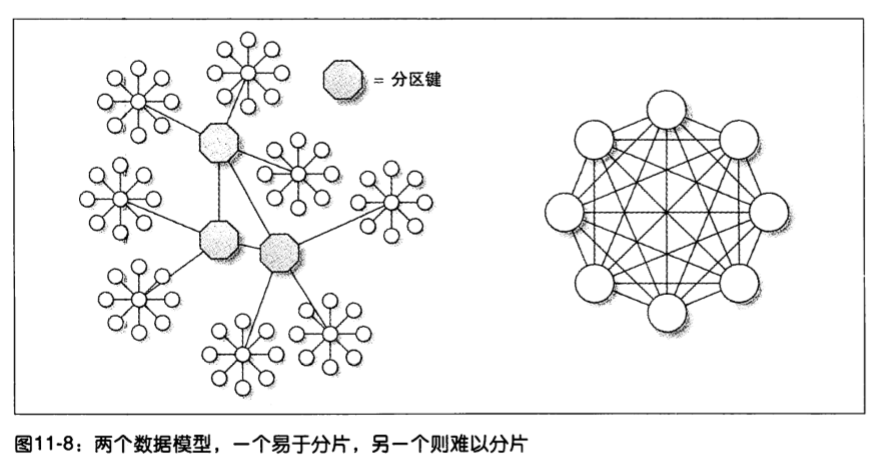
选择分区键(partitioning key)
一个好的分区键常常是数据库中非常重要的实体的主键。选择分区键时要尽可能跨分片查询,同时要让分片足够小,且分布均匀。
多个分区键
有多个分区键时要设计一定的冗余字段,减少分片查询
跨分片查询
跨分片查询可以借助汇总表来执行,遍历所以分片来形成汇总表,然后将结果缓存。
分片数据、分片和节点
分片和节点并不一定是一对一的关系,应该近可能让分片的大小比节点容量小,这样就可以在单个节点上存储多个分片。
小的分片更容易管理,在当 100G 的表上增加索引的时间比在 100 个 1G 分片上执行的总时间更长。小分片也更加便于转移。
在节点上部署分片
固定分配
动态分配
混合动态分配和固定分配
显式分配
分片数据均衡
生成全局唯一 ID
分片工具
通过多实例扩展
不要在一太性能强悍的服务器上只运行一个数据库实例,可以让数据分片足够小,在每台机器上放置多个分片,充分发挥硬件性能。
通过集群扩展
作为关系型数据库,MySQL 本身难以通过集群扩展。目前见到的通常都是将 NoSQL 和 SQL 结合的技术。如 MySQL Cluster(NDB Cluster)并不是一个 SQL 数据库,它是一个可扩展的数据库,有一套独立的 API,但也可以在前端使用 MySQL 存储引擎支持 SQL 查询。
向内扩展
这种策略只能作为短期的缓兵之计,难以应对数据的高速增长。
清理数据时应考虑以下几点:
- 对应用的影响:操作数据时平衡归档的行数和事务的大小,避免影响正常业务
- 要归档的行:数据不再使用后可以立即清除也可以通过应用定期清除。可以吧归档数据放在核心表的同数据库中,通过视图访问,也可以完全转移到其他数据库
- 维护数据一致性:当表之间存在关系时,需要考虑表的的归档顺序。在应用层有层次联系时,归档的顺序应该与其一致。归档过程中可以暂时关闭外键约束。
- 避免数据丢失:为避免数据丢失,删数据之前要保证数据已经在目标机器上保存好(数据库或文件的形式都行)。可以将归档任务设计为随时启动或关闭,并且不会引起不一致或索引冲突。
- 解除归档:通过设置检查点确定数据是否需要归档,并支持回退。比如在登录验证时,如果用户不存在导致登录失败,可以检查归档数据中是否存在该用户,如果有,取回来。
即使不把老数据转移,将活跃数据和非活跃数据隔离也有助于提高缓存效率,也可以对不同的数据使用不同的硬件或架构。
- 分表
- 分区
- 基于时间的数据分区:新数据存在大内存和高速硬盘的主机上,大量的老数据存储在大容量主机上。
注:分表和分区的区别,分表将表在逻辑拆分成不同的表;分区还是保持原来的逻辑表但在存储时将数据分成小块,分区存放。
负载均衡
典型的大型网站负载均衡设置,做两层负载均衡,一个负责应用访问负载均衡,一个负载 MySQL 读取查询负载均衡。
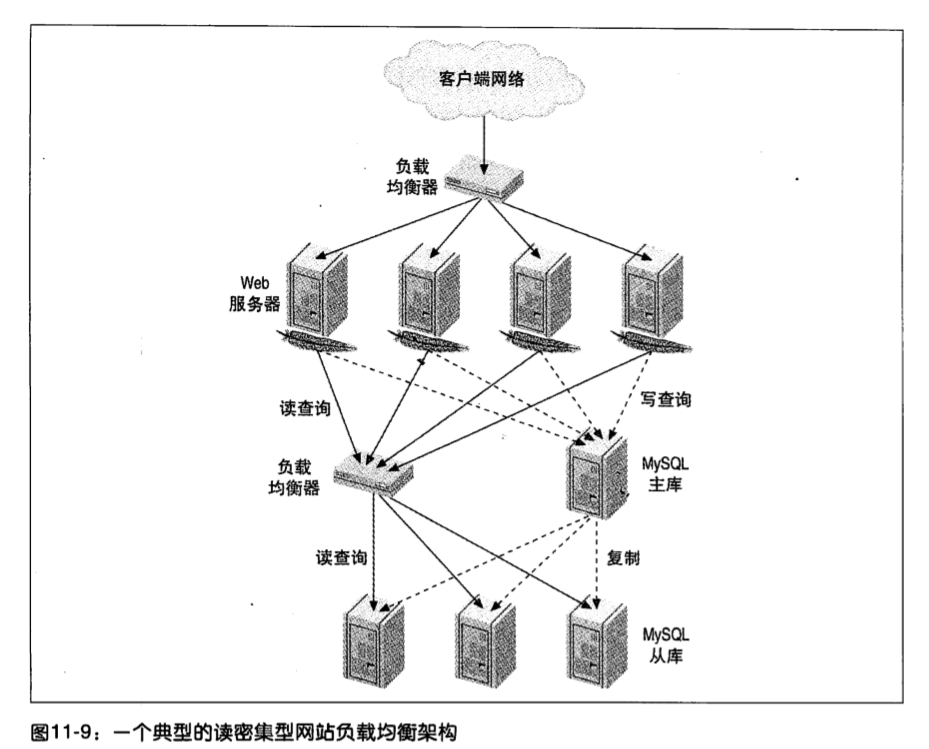
负载均衡的五个要点:
- 可扩展性:有助于读写分离时配置从多个备库读数据
- 高效性:有助于更有效地使用资源
- 可用性:时刻保持可用的服务器
- 透明性:客户端无须关注负载均衡设置,访问一个逻辑服务器即可
- 一致性:如果应用是有状态的(数据库事务,网站会话等),那么负载均衡应该将相关查询指向同一个服务器。应用无须跟踪连接是是哪个服务器。
直接连接
在保持应用和数据库之前的情况下进行负载均衡,应用高效执行数据查询路由。
异步复制容易产生脏数据,常见的读/写分离方法:
- 基于查询分离:将不能容忍脏数据的分配到主库上,不常用
- 基于脏数据分离:让应用检查复制延迟,一确定备库数据是否过时,定时统一更新。报表类应用常用策略
- 基于会话分离
- 基于版本分离
- 基于全局版本/会话分离
引入中间件
负载均衡器
较少有专门为 MySQL 设计的负载均衡器。可使用多用途负载均衡器,但缺少 MySQL 特性,使用是有限制
负载均衡算法
- 随机
- 轮询
- 最少连接数
- 最快响应
- 哈希
- 权重